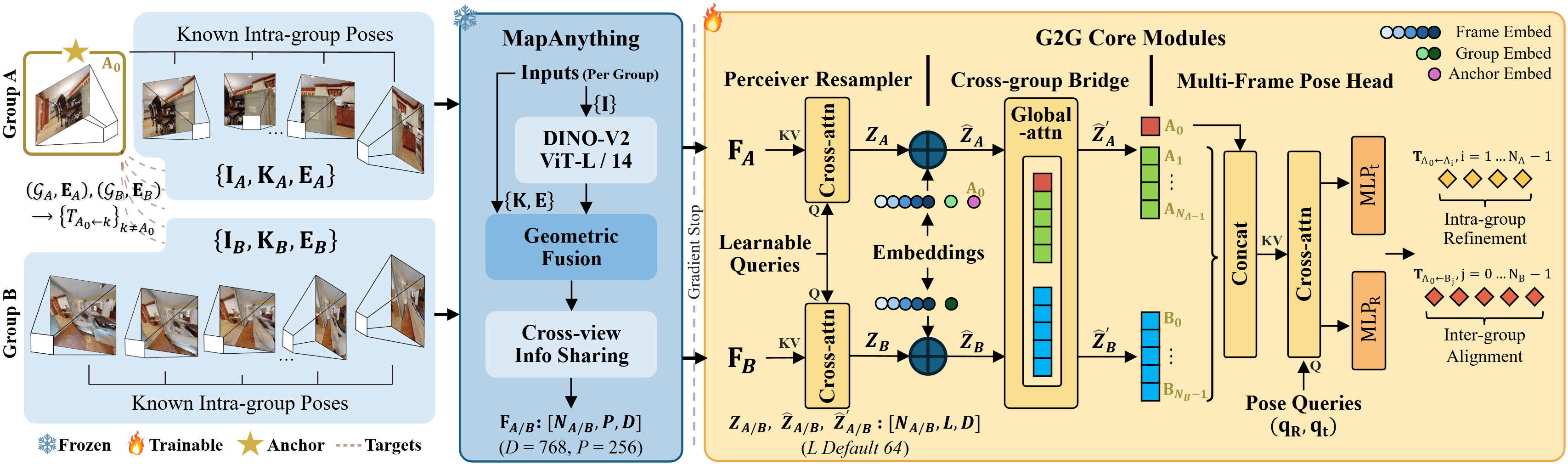
Framework. A frozen multi-view backbone (MapAnything, DINO-V2 ViT-L/14) encodes each group's geometry. Three lightweight trainable modules (a perceiver resampler, a cross-group bridge with merged self-attention, and a multi-frame pose head) jointly refine the intra-group representations and regress the inter-group relative 6-DoF pose.